Qwen3-TTS Base とは?何者?
Qwen3-TTS-12Hz-1.7B-Base / Qwen3-TTS-12Hz-0.6B-Base は、Alibaba が公開している Qwen3-TTS ファミリーの中でも「高品質ボイスクローン用のベースモデル」です。
特徴をざっくり言うと:
- 参照音声(自分の声)+その文字起こしを渡すと、かなりそれっぽい声質で喋ってくれる
- マルチリンガル対応で、日本語も自然なイントネーション
という特徴があります。実は声優さんの声でもいけるらしい?です。
好きなセリフを、好きな声で、好きなタイミングで作成できるのが特徴です。
今回はこの Qwen3 TTS Base を Windows 11 上でローカル実行し、PowerShell や既存ツールから「棒読みちゃん互換」で叩ける TTS サーバに仕立てます。
最終的には:
http://localhost:50081/Talkに POST でテキストを投げる
→ 棒読みちゃんは50080ですが、あえて同時起動できるように +1 しています- キューに溜めて、1件ずつ音声生成 → ファイル保存 → 再生
- 自分の声クローンで、テンポ速め・ピッチ維持・末尾ブツ切れ対策済の音声
という「なんちゃって棒読みちゃん(中身はQwen3)」が動くところまで行きます。
今回はCPUベースで行いますが、GPUでの動作でもできるように随時コメントを追加しています。
1. 環境準備:Windows 11 上に Python + ライブラリを整える
1-1. Python 3.10〜3.12 を用意する
Qwen3-TTS と onnxruntime の組み合わせは、最新すぎる Python(3.13〜)だとホイールがなくてハマります。
安全圏は 3.10〜3.12 なので、以下のどれかで揃えておきます:
- 公式サイトから Python 3.12 x64 をインストール
- https://www.python.org/downloads/release/python-31210/ から Windows 用インストーラ
- インストール時、下部にある「Add python.exe to PATH」にチェックして「Install Now」を押す
- 既に 3.12 が入っているなら、それを使って仮想環境を作ることもできます。
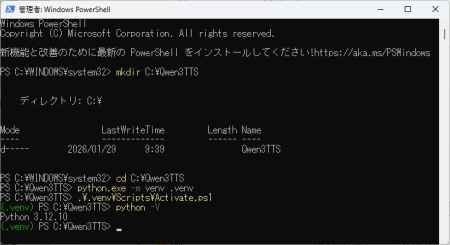
1-2. 作業フォルダと仮想環境の作成
PowerShell を開いて、下記のようなパスを実行します。太字のコマンドを実行してください。
powershellPS C:\> mkdir C:\Qwen3TTS
PS C:\> cd C:\Qwen3TTS
# Python 3.12 のパスが通ていない場合は環境に合わせて変更
PS C:\Qwen3TTS> python.exe -m venv .venv
PS C:\Qwen3TTS> .\.venv\Scripts\Activate.ps1
(.venv) PS C:\Qwen3TTS> python -V# → 3.12.x を確認
以降はこの仮想環境上で作業します。
1-3. 必要ライブラリのインストール
TTS 本体+音声入出力+Web サーバをまとめて入れます。太字のコマンドを実行してください。
(.venv) PS C:\Qwen3TTS> python -m pip install -U pip
# PyTorch(CPU版)。GPUがあればCUDA版でもOK pip install torch torchaudio --index-url https://download.pytorch.org/whl/cu128(.venv) PS C:\Qwen3TTS> pip install torch torchaudio --index-url https://download.pytorch.org/whl/cpu
# onnxruntime(qwen-tts が要求)
(.venv) PS C:\Qwen3TTS> pip install onnxruntime
# Qwen3-TTS ラッパー
(.venv) PS C:\Qwen3TTS> pip install qwen-tts
# 音声入出力
(.venv) PS C:\Qwen3TTS> pip install soundfile sounddevice
# Webサーバ(棒読みちゃん互換API用)
(.venv) PS C:\Qwen3TTS> pip install fastapi uvicorn
# ピッチを変えずに話速を変えるためのタイムストレッチ
(.venv) PS C:\Qwen3TTS> pip install --upgrade audiostretchy
ここまで通れば、ライブラリの地獄はほぼ脱出です。
2. 自分の声を録音して「参照音声+スクリプト」を用意する
2-1. 参照音声(my_voice_sample.wav)を作成
- Windows の「ボイスレコーダー」などで、10秒程度の音声を録音します
- 内容はハッキリ・一定のトーンで、環境ノイズ少なめが理想
- 例:
「春の朝、私は7時30分に起き、白いカップで熱いコーヒーを飲みました。今日は2026年1月27日、天気は晴れ、気温は6度です。静かな部屋で深呼吸し、落ち着いた声で一文ずつ、正確に読み上げます。」
- 例:
- 録音を WAV(16bit/24bit, 44.1kHz〜48kHz)として保存し、
C:\Qwen3TTS\my_voice_sample.wavという名前にします。
2-2. 文字起こし(REF_TEXT)を用意する
録音するときに使用した文を、誤字なしで1行の文字列にします。この分は後でPythonスクリプトに組み込みます。これは Qwen3-TTS が「この音声はこの文章を読んでいる」と認識するためのラベルで、クローン精度を上げるために必要です。
3. まずは単発テスト:0.6B-Base で自分の声クローン
本格的なサーバ構築の前に、スタンドアロンで 1ファイルだけ喋らせてみます。
C:\Qwen3TTS\qwen3_voice_clone_06b.py を作成して、以下の内容を保存します。
# file: qwen3_voice_clone_06b.py
import torch
import soundfile as sf
from qwen_tts import Qwen3TTSModel
MODEL_ID = "Qwen/Qwen3-TTS-12Hz-0.6B-Base" # GPUがあれば "Qwen/Qwen3-TTS-12Hz-1.7B-Base"
DEVICE_MAP = "cpu" # GPUがあれば "cuda:0"
DTYPE = torch.float32 # GPUなら torch.bfloat16 でもOK
REF_AUDIO = "my_voice_sample.wav"
# 録音するときに使用した文ここで組み込み
REF_TEXT = (
"春の朝、私は7時30分に起き、白いカップで熱いコーヒーを飲みました。"
"今日は2026年1月27日、天気は晴れ、気温は6度です。"
"静かな部屋で深呼吸し、落ち着いた声で一文ずつ、正確に読み上げます。"
)
# 出力する文字を指定
TARGET_TEXT = "こんにちは!私はAIです。すごい時代になりましたね。漢字を読むのは苦手です。"
OUTPUT_WAV = "my_clone_voice_06b.wav"
def main():
print("モデル読み込み中...")
model = Qwen3TTSModel.from_pretrained(
MODEL_ID,
device_map=DEVICE_MAP,
dtype=DTYPE,
)
print("ボイスクローン用プロンプト作成中...")
prompt = model.create_voice_clone_prompt(
ref_audio=REF_AUDIO,
ref_text=REF_TEXT,
x_vector_only_mode=False,
)
print("音声生成中...")
wavs, sr = model.generate_voice_clone(
text=TARGET_TEXT,
voice_clone_prompt=prompt,
language="Japanese",
)
print("ファイル保存中:", OUTPUT_WAV)
sf.write(OUTPUT_WAV, wavs[0], sr)
print("完了:", OUTPUT_WAV, "sr:", sr)
if __name__ == "__main__":
main()
実行:
(.venv) PS C:\Qwen3TTS> python qwen3_voice_clone_06b.py
同じフォルダに my_clone_voice_06b.wav ができるので、再生して「自分っぽく聞こえるか」をチェック。
ここまでOKなら、次は「高速化&サーバ化」に進みます。
4. 高速化:プロンプトキャッシュ+ピッチ維持の速度変更
Qwen3 TTS Base はそれなりに重いので、毎回 create_voice_clone_prompt を呼ぶと結構待たされます。
そこで:
- 参照音声から作った
voice_clone_promptをファイルに保存 - 起動時・次回以降はキャッシュを読み込むだけ
- 生成された WAV に対して、ピッチ保持タイムストレッチでテンポだけ速く
というパターンにします。
これは棒読みちゃんサーバ側に最初から組み込むので、ここではイメージだけ押さえておけばOKです。
5. 棒読みちゃん互換サーバを組み立てる
いよいよ本番。C:\Qwen3TTS\bouyomi_qwen3_server.py を作成し、以下を丸ごと入れます。
# file: bouyomi_qwen3_server.py
import os
import pickle
import threading
import queue# file: bouyomi_qwen3_server.py
import os
import pickle
import threading
import queue
import time
from typing import Optional
import numpy as np
import torch
import soundfile as sf
import sounddevice as sd
from fastapi import FastAPI, Form
from fastapi.responses import PlainTextResponse
from qwen_tts import Qwen3TTSModel
from audiostretchy.stretch import stretch_audio # ピッチ保持タイムストレッチ
# ===== Qwen3-TTS 設定 =====
MODEL_ID = "Qwen/Qwen3-TTS-12Hz-1.7B-Base"
DEVICE_MAP = "cpu" # GPUがあれば "cuda:0"
DTYPE = torch.float32 # GPUなら torch.bfloat16
REF_AUDIO = "my_voice_sample.wav"
REF_TEXT = (
"春の朝、私は7時30分に起き、白いカップで熱いコーヒーを飲みました。"
"今日は2026年1月27日、天気は晴れ、気温は6度です。"
"静かな部屋で深呼吸し、落ち着いた声で一文ずつ、正確に読み上げます。"
)
OUTPUT_DIR = "outputs"
MODEL_SAFE_NAME = MODEL_ID.replace("/", "_").replace(":", "_")
PROMPT_CACHE_PATH = f"voice_prompt_{MODEL_SAFE_NAME}.pt"
SPEED_FACTOR = 1.2 # 1.2倍速(テンポだけ速く)
FADE_OUT_SEC = 0.15
TAIL_SILENCE_SEC = 0.25
SERVER_PORT = 50081 # 必要に応じて変更
# ===== グローバル状態 =====
app = FastAPI()
qwen_model: Optional[Qwen3TTSModel] = None
voice_clone_prompt = None
play_queue: "queue.Queue[dict]" = queue.Queue()
player_thread_started = False
player_thread_lock = threading.Lock()
# ===== Qwen3-TTS 関連 =====
def load_model() -> Qwen3TTSModel:
global qwen_model
if qwen_model is None:
print(f"[Qwen3] モデル読み込み中... ({MODEL_ID})")
qwen_model = Qwen3TTSModel.from_pretrained(
MODEL_ID,
device_map=DEVICE_MAP,
dtype=DTYPE,
)
return qwen_model
def build_or_load_voice_prompt(model: Qwen3TTSModel):
global voice_clone_prompt
if voice_clone_prompt is not None:
return voice_clone_prompt
if os.path.exists(PROMPT_CACHE_PATH):
print(f"[Qwen3] 既存プロンプトを読み込み中... ({PROMPT_CACHE_PATH})")
with open(PROMPT_CACHE_PATH, "rb") as f:
voice_clone_prompt = pickle.load(f)
return voice_clone_prompt
print("[Qwen3] ボイスクローン用プロンプト作成中...")
voice_clone_prompt = model.create_voice_clone_prompt(
ref_audio=REF_AUDIO,
ref_text=REF_TEXT,
x_vector_only_mode=False,
)
print(f"[Qwen3] プロンプトをキャッシュに保存中... ({PROMPT_CACHE_PATH})")
with open(PROMPT_CACHE_PATH, "wb") as f:
pickle.dump(voice_clone_prompt, f)
return voice_clone_prompt
def apply_tail_fade_and_silence(wav: np.ndarray, sr: int) -> np.ndarray:
"""末尾フェード+無音で「ブツッ」と切れるのを防ぐ。"""
wav = wav.astype(np.float32)
fade_samples = int(FADE_OUT_SEC * sr)
if fade_samples > 0 and fade_samples < wav.shape[0]:
fade = np.linspace(1.0, 0.0, fade_samples, endpoint=True, dtype=np.float32)
start = wav.shape[0] - fade_samples
wav[start:] *= fade
silence_samples = int(TAIL_SILENCE_SEC * sr)
if silence_samples > 0:
silence = np.zeros(silence_samples, dtype=np.float32)
wav = np.concatenate([wav, silence], axis=0)
return wav
def tts_generate_to_file(text: str, index: int) -> str:
"""テキストからWAVを生成してファイル保存し、そのパスを返す。"""
os.makedirs(OUTPUT_DIR, exist_ok=True)
model = load_model()
prompt = build_or_load_voice_prompt(model)
print(f"[Qwen3] 音声生成中... (#{index}) text={text[:30]}...")
wavs, sr = model.generate_voice_clone(
text=text,
voice_clone_prompt=prompt,
language="Japanese",
)
wav = wavs[0].astype(np.float32)
# 末尾処理
wav = apply_tail_fade_and_silence(wav, sr)
# [-1, 1] を 16bit PCM スケールにクリップ・変換
peak = np.max(np.abs(wav)) if wav.size > 0 else 0.0
if peak > 1.0:
wav = wav / peak
wav_int16 = np.int16(np.clip(wav, -1.0, 1.0) * 32767)
# 等速版を一時ファイルに16bitで保存
base_path = os.path.join(OUTPUT_DIR, f"bouyomi_base_{index:05d}.wav")
sf.write(base_path, wav_int16, sr, subtype="PCM_16")
# ピッチを維持したまま速度変更
if SPEED_FACTOR != 1.0:
ratio = 1.0 / SPEED_FACTOR # 速く → ratio < 1.0
print(f"[Qwen3] ピッチ保持タイムストレッチ中... ratio={ratio:.3f}")
out_path = os.path.join(OUTPUT_DIR, f"bouyomi_{index:05d}.wav")
stretch_audio(
base_path,
out_path,
ratio=ratio,
)
else:
out_path = os.path.join(OUTPUT_DIR, f"bouyomi_{index:05d}.wav")
os.replace(base_path, out_path)
print(f"[Qwen3] ファイル保存完了: {out_path}")
return out_path
def play_wav_file(path: str):
"""WAVファイルを再生して、再生完了までブロック。"""
print(f"[Player] 再生開始: {path}")
# ここも 16bit PCM 前提の読み出しでOK
data, sr = sf.read(path, dtype="int16")
data = data.astype(np.float32) / 32767.0 # sounddevice に float32 で渡す
sd.stop()
sd.play(data, sr)
sd.wait()
sd.stop()
print(f"[Player] 再生終了: {path}")
# ===== 再生スレッド =====
def player_loop():
index = 1
while True:
item = play_queue.get()
try:
text = item.get("text", "")
req_id = item.get("id", index)
if not text:
print("[Player] 空テキストをスキップ")
continue
print(f"[Player] キュー処理開始: id={req_id}, text={text[:30]}...")
wav_path = tts_generate_to_file(text, index=req_id)
play_wav_file(wav_path)
print(f"[Player] キュー処理完了: id={req_id}")
index += 1
except Exception as e:
print("[Player] エラー:", e)
finally:
play_queue.task_done()
def ensure_player_thread_running():
global player_thread_started
with player_thread_lock:
if not player_thread_started:
print("[Player] 再生スレッド起動")
t = threading.Thread(target=player_loop, daemon=True)
t.start()
player_thread_started = True
# ===== FastAPI エンドポイント =====
@app.post("/Talk", response_class=PlainTextResponse)
async def talk(
text: str = Form(...),
speed: int = Form(0),
tone: int = Form(0),
volume: int = Form(0),
voice: int = Form(0),
command: int = Form(0),
):
"""棒読みちゃんの /Talk っぽいインタフェース。"""
if not text:
return "NG"
ensure_player_thread_running()
req_id = int(time.time() * 1000)
item = {"text": text, "id": req_id, "created_at": time.time()}
play_queue.put(item)
print(f"[API] キュー追加: id={req_id}, text={text[:30]}... (queue size={play_queue.qsize()})")
return "OK"
@app.get("/health", response_class=PlainTextResponse)
async def health():
return "OK"
if __name__ == "__main__":
# 起動時にモデルとプロンプトをロード
m = load_model()
build_or_load_voice_prompt(m)
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=SERVER_PORT)
import time
from typing import Optional
import numpy as np
import torch
import soundfile as sf
import sounddevice as sd
from fastapi import FastAPI, Form
from fastapi.responses import PlainTextResponse
from qwen_tts import Qwen3TTSModel
from audiostretchy.stretch import stretch_audio
# ===== Qwen3-TTS 設定 =====
MODEL_ID = "Qwen/Qwen3-TTS-12Hz-0.6B-Base"
DEVICE_MAP = "cpu" # GPUがあれば "cuda:0"
DTYPE = torch.float32 # GPUなら torch.bfloat16
REF_AUDIO = "my_voice_sample.wav"
REF_TEXT = (
"春の朝、私は7時30分に起き、白いカップで熱いコーヒーを飲みました。"
"今日は2026年1月27日、天気は晴れ、気温は6度です。"
"静かな部屋で深呼吸し、落ち着いた声で一文ずつ、正確に読み上げます。"
)
OUTPUT_DIR = "outputs"
MODEL_SAFE_NAME = MODEL_ID.replace("/", "_").replace(":", "_")
PROMPT_CACHE_PATH = f"voice_prompt_{MODEL_SAFE_NAME}.pt"
SPEED_FACTOR = 1.2 # 1.2倍速(テンポだけ速く)
FADE_OUT_SEC = 0.15
TAIL_SILENCE_SEC = 0.25
SERVER_PORT = 50081 # 使用ポート(必要なら変更)
# ===== グローバル状態 =====
app = FastAPI()
qwen_model: Optional[Qwen3TTSModel] = None
voice_clone_prompt = None
play_queue: "queue.Queue[dict]" = queue.Queue()
player_thread_started = False
player_thread_lock = threading.Lock()
# ===== Qwen3-TTS 関連 =====
def load_model() -> Qwen3TTSModel:
global qwen_model
if qwen_model is None:
print(f"[Qwen3] モデル読み込み中... ({MODEL_ID})")
qwen_model = Qwen3TTSModel.from_pretrained(
MODEL_ID,
device_map=DEVICE_MAP,
dtype=DTYPE,
)
return qwen_model
def build_or_load_voice_prompt(model: Qwen3TTSModel):
global voice_clone_prompt
if voice_clone_prompt is not None:
return voice_clone_prompt
if os.path.exists(PROMPT_CACHE_PATH):
print(f"[Qwen3] 既存プロンプトを読み込み中... ({PROMPT_CACHE_PATH})")
with open(PROMPT_CACHE_PATH, "rb") as f:
voice_clone_prompt = pickle.load(f)
return voice_clone_prompt
print("[Qwen3] ボイスクローン用プロンプト作成中...")
voice_clone_prompt = model.create_voice_clone_prompt(
ref_audio=REF_AUDIO,
ref_text=REF_TEXT,
x_vector_only_mode=False,
)
print(f"[Qwen3] プロンプトをキャッシュに保存中... ({PROMPT_CACHE_PATH})")
with open(PROMPT_CACHE_PATH, "wb") as f:
pickle.dump(voice_clone_prompt, f)
return voice_clone_prompt
def apply_tail_fade_and_silence(wav: np.ndarray, sr: int) -> np.ndarray:
"""末尾フェード+無音で「ブツッ」と切れるのを防ぐ。"""
wav = wav.astype(np.float32)
fade_samples = int(FADE_OUT_SEC * sr)
if fade_samples > 0 and fade_samples < wav.shape[0]:
fade = np.linspace(1.0, 0.0, fade_samples, endpoint=True, dtype=np.float32)
start = wav.shape[0] - fade_samples
wav[start:] *= fade
silence_samples = int(TAIL_SILENCE_SEC * sr)
if silence_samples > 0:
silence = np.zeros(silence_samples, dtype=np.float32)
wav = np.concatenate([wav, silence], axis=0)
return wav
def tts_generate_to_file(text: str, index: int) -> str:
"""テキストからWAVを生成してファイル保存し、そのパスを返す。"""
os.makedirs(OUTPUT_DIR, exist_ok=True)
model = load_model()
prompt = build_or_load_voice_prompt(model)
print(f"[Qwen3] 音声生成中... (#{index}) text={text[:30]}...")
wavs, sr = model.generate_voice_clone(
text=text,
voice_clone_prompt=prompt,
language="Japanese",
)
wav = wavs[0].astype(np.float32)
# 末尾処理
wav = apply_tail_fade_and_silence(wav, sr)
# 等速版を一時ファイルに保存
base_path = os.path.join(OUTPUT_DIR, f"bouyomi_base_{index:05d}.wav")
sf.write(base_path, wav, sr, subtype="FLOAT")
# ピッチを維持したまま速度変更
if SPEED_FACTOR != 1.0:
ratio = 1.0 / SPEED_FACTOR # 速く → ratio < 1.0
print(f"[Qwen3] ピッチ保持タイムストレッチ中... ratio={ratio:.3f}")
out_path = os.path.join(OUTPUT_DIR, f"bouyomi_{index:05d}.wav")
stretch_audio(
base_path,
out_path,
ratio=ratio,
)
else:
out_path = os.path.join(OUTPUT_DIR, f"bouyomi_{index:05d}.wav")
os.replace(base_path, out_path)
print(f"[Qwen3] ファイル保存完了: {out_path}")
return out_path
def play_wav_file(path: str):
"""WAVファイルを再生して、再生完了までブロック。"""
print(f"[Player] 再生開始: {path}")
data, sr = sf.read(path, dtype="float32")
sd.stop()
sd.play(data, sr)
sd.wait()
sd.stop()
print(f"[Player] 再生終了: {path}")
# ===== 再生スレッド =====
def player_loop():
index = 1
while True:
item = play_queue.get()
try:
text = item.get("text", "")
req_id = item.get("id", index)
if not text:
print("[Player] 空テキストをスキップ")
continue
print(f"[Player] キュー処理開始: id={req_id}, text={text[:30]}...")
wav_path = tts_generate_to_file(text, index=req_id)
play_wav_file(wav_path)
print(f"[Player] キュー処理完了: id={req_id}")
index += 1
except Exception as e:
print("[Player] エラー:", e)
finally:
play_queue.task_done()
def ensure_player_thread_running():
global player_thread_started
with player_thread_lock:
if not player_thread_started:
print("[Player] 再生スレッド起動")
t = threading.Thread(target=player_loop, daemon=True)
t.start()
player_thread_started = True
# ===== FastAPI エンドポイント =====
@app.post("/Talk", response_class=PlainTextResponse)
async def talk(
text: str = Form(...),
speed: int = Form(0),
tone: int = Form(0),
volume: int = Form(0),
voice: int = Form(0),
command: int = Form(0),
):
"""棒読みちゃんの /Talk っぽいインタフェース。"""
if not text:
return "NG"
ensure_player_thread_running()
req_id = int(time.time() * 1000)
item = {"text": text, "id": req_id, "created_at": time.time()}
play_queue.put(item)
print(f"[API] キュー追加: id={req_id}, text={text[:30]}... (queue size={play_queue.qsize()})")
return "OK"
@app.get("/health", response_class=PlainTextResponse)
async def health():
return "OK"
if __name__ == "__main__":
# 起動時にモデルとプロンプトをロード
m = load_model()
build_or_load_voice_prompt(m)
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=SERVER_PORT)
6. サーバの起動とテスト
6-1. サーバ起動
(.venv) PS C:\Qwen3TTS> python bouyomi_qwen3_server.py
- 初回はモデルのダウンロード&プロンプト作成が入るので少し待ちます。
Application startup complete.的なメッセージが出たら待ち受け開始です。- Windowsファイヤウォールのメッセージが出たら許可してください。
6-2. テストで /Talk を叩く
別の PowerShell から:
C:\Qwen3TTS> Invoke-WebRequest -Uri "http://localhost:50081/Talk" -Method POST -Body @{ text = "テスト1です。Qwen3-TTSで喋っています。" }
PS C:\Qwen3TTS> Invoke-WebRequest -Uri "http://localhost:50081/Talk" -Method POST -Body @{ text = "テスト2です。キューに溜めた2件目です。" }
- サーバ側コンソールには
[API] キュー追加→[Player] キュー処理開始→[Qwen3] 音声生成中...→[Player] 再生開始というログが順番に流れます。 - 音声は 1件ずつ、前の再生が終わってから次が流れます。
- WAV は
outputsフォルダにbouyomi_*.wavとして全部残るので、あとから確認も可能です。
7. 面白いですね、これ
AI(LLM)が出てきて、一気にいろいろなものが進んできており、すごい時代になったものです。
今回の構築では「ローカルの Windows マシンが、自分専用の“喋るエージェント”になった」という点がすごいことだと思います。
Qwen3-TTS-12Hz-1.7B-Base は、クラウドAPIを叩かなくても、自分の声そっくりの音声をかなり高いクオリティで生成してくれます。そこに FastAPI で HTTP サーバをかぶせ、棒読みちゃん互換の /Talk エンドポイントを用意したことで、既存のスクリプトやツールから「棒読みちゃんに送るノリのまま」自分クローンボイスを呼び出せるようになりました。
内部では、参照音声+文字起こしから生成したボイスクローンプロンプトをキャッシュしておき、毎回のリクエストではそれを再利用して低オーバーヘッドで生成する構成にしています。生成後の WAV には末尾のフェードアウトと無音を足し、さらにタイムストレッチでピッチを維持したままテンポだけ速くしているので、「早口だけどブツ切れない、ちゃんと滑らかな読み上げ」になっているのもポイントです。
ニュース読み上げ・チャットログ読み上げ・通知読み上げといった用途に、そのまま流用しやすい小さな音声基盤になりました。ここに「テキスト整形」や「感情プロンプト」を足していけば、もっと人間らしい喋り方や状況に応じたトーンの切り替えも狙えます。今回の構成をベースにして、
- 別の声(別の参照音声)を増やして複数ボイスに対応する
- クライアント側から
voiceやspeedパラメータを受けて切り替える - OBS や配信ソフトと組み合わせて「自分ボイスの読み上げ配信」をする
といった方向にも簡単に伸ばしていけるはずです。
「棒読みちゃんを自分で作り直した」みたいな感覚で遊べるので、興味のある人はぜひ自分の Windows 環境でも試して、少しずつ好みの“自分ボイスエージェント”に育ててみてください。