巷で話題のオープンソースLLMを使ってみたい!
ということで今回は、かなり前の世代のサーバーである HPE ProLiant DL360 Gen9 に、ローカルLLM実行環境として人気の LM Studio を導入し、大規模モデルの一つである openai/gpt-oss-120b を動作さてみましたので、その仕様メモを共有します。結論から言うと「とりあえず動くけど、やっぱり遅い」という結果になりました(笑)
検証環境
- サーバー: HPE ProLiant DL360 Gen9
- CPU: Intel Xeon E5-2623 v4 @ 2.60GHz (1基搭載)
- メモリ: 192GB DDR4
- ストレージ: HDD 300GB SAS (RAID-1)
- OS: Windows 10 Pro
- ローカルLLMランタイム: LM Studio 0.3.23
- 実行モデル: openai/gpt-oss-120b
LM Studio のインストールとモデルのダウンロード
LM Studio のインストール自体は非常に簡単です。公式サイトからダウンロードし、インストールして実行するだけです。
初回起動時にgpt-oss-20bをダウンロードしようとしますがお断り(スキップ)しています。openai/gpt-oss-120b モデルは、LM Studio 内の左下虫眼鏡の検索機能を使って簡単に見つけることができます。今回は Q4_K_M 量子化バージョンをダウンロードしました。このモデルファイルは量子化されていても非常に大きく約 63.39 GB でした。
モデルのロードと実行
LM Studio を起動し、ダウンロードした gpt-oss-120b をロードします。ロード自体には、サーバーのI/O性能にもよりますが数分かかります。
そして、いよいよチャットインターフェースでプロンプトを送信してみます。
動作確認
プロンプト「自己紹介をしてください」に対する応答は、確かに生成されました。内容も自然な日本語で、モデルの性能自体は問題なさそうです。
パフォーマンスの課題
しかし、応答速度はかなり遅いと言わざるを得ません。トークンの生成が始まってからも、1文字ずつゆっくりと現れるような感覚です。短文の生成でも数秒~数十秒、長文になれば1分以上かかることも珍しくありませんでした。
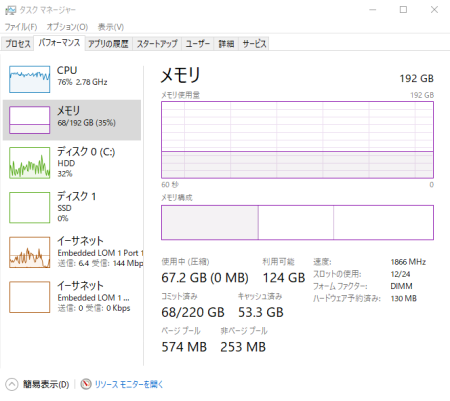
LM Studio のリソースモニターを確認すると、CPU使用率はかなり高めを推移し、メモリもモデルロード後は常に50GB以上が消費されている状態でした。特にCPUのコア数が多くても、シングルスレッド性能がボトルネックになっている箇所も散見されました。
仕様メモと考察
- モデルサイズ: openai/gpt-oss-120b の Q4_K_M 量子化版は約 63GB。このサイズから、やはり大量のメモリ(RAMまたはVRAM)が必要になります。今回は192GBの潤沢なRAMがあったため、メモリ不足でクラッシュすることはありませんでした。
- メモリ消費: モデルのロードと実行には、上記のモデルサイズに加え、LM Studio自体やOSのオーバーヘッド、そして推論時のテンポラリ領域などで、最終的には65GB以上のRAMが消費されます。
- CPU依存性: DL360 Gen9 の Xeon E5 v4 は、当時のサーバー向けCPUとしては高性能でしたが、現代のLLM推論においては、特に AVX-512 命令セットに対応した最新世代のCPUや、さらに言えばGPUの推論性能には遠く及びません。LM Studio はCPU推論も可能ですが、やはり大規模モデルでは処理能力が不足します。
- ディスクI/O: モデルファイルのロードやスワップ発生時などに、ストレージの速度も影響します。
- 遅延の要因: 主な遅延要因は、やはりCPUの演算能力不足と、モデルサイズに対するメモリ帯域幅の限界にあるかと。GPUを使用しない場合、モデルの全パラメータをCPUで処理する必要があるため、計算負荷が非常に高くなります。
まとめ
HPE ProLiant DL360 Gen9 で openai/gpt-oss-120b を動かすことは「可能」でしたが、「実用的」とは言い難い結果となりました。これは、あくまでCPUベースの推論であり、この規模のモデルにはやはり専用のGPUアクセラレータ(特にVRAM容量の大きいもの)が必須です。
生成されたトークンのスピードは、3.32 tok/sec 877 tokens 14.10s to first token でした。
しかし、古いサーバーを再活用してLLMに触れてみる、という点ではいいかんじです。とりあえず動くというのが感動します。
- メリット:
- 既存のサーバーリソースを有効活用できる。HP Gen9はヤフオクで1万円で買えるので。
- LM Studio の手軽さで、比較的簡単に大規模モデルを試せる。
- デメリット:
- 推論速度が非常に遅い。くそ遅い。待ちきれない。
- 消費電力に対するパフォーマンスが悪い。あと音もうるさい。
- DL360 Gen9 に高性能GPUを搭載するのは難しい(電源や冷却、PCIeスロットの制約)。
もし、居ないとは思うけど、古いサーバーでLLMを動かすことを検討されているのであれば、より小規模なモデル(例: Llama 7B/13B クラス)であれば、もう少し実用的な速度で動作する可能性があります。あるいは、GPU搭載可能なサーバーやワークステーションに移行することが、LLMの本格的な活用には不可欠と言えるでしょう。
今回の検証が、同様の環境でLLMのローカル実行を検討されている方の参考になれば幸いです。
 |
新品価格 |
真面目に、Ryzen AI Max+ 395 に 128GB メモリが搭載されたものを買ったほうが幸せですよ!
一時期、在庫がなくなっていましたが復活しているようです。マジほしい・・・。